向量数据库简介
向量
向量是一个有大小和方向的量。在二维空间中一般使用(a,b)表示。
加法:(a,b)+(c,d)=(a+c,b+d)
减法:(a,b)-(c,d)=(a-c,b-d)
乘法:(a,b)*c=(a*c,b*c)
点积:(a,b)· (c,d)=ac+bd
文字转化向量
举例说“我爱我家”这句话怎么转化
1 | "我" 的向量表示:[0.1, 0.2, 0.3, ...] |
对于这个句子,我们可以将每个词的向量表示进行合并或平均,得到整个句子的向量表示。以下是两种常见的方式:
- 向量合并(Vector Concatenation):将每个词的向量连接在一起,形成句子的向量表示。对于 “我爱我家” 这个句子,合并后的向量表示可以是:[0.1, 0.2, 0.3, …, 0.4, 0.5, 0.6, …, 0.7, 0.8, 0.9, …]。
- 平均向量(Average Vector):将每个词的向量相加并求平均,得到句子的向量表示。对于 “我爱我家” 这个句子,平均后的向量表示可以是:[ (0.1+0.4+0.7)/3 , (0.2+0.5+0.8)/3 , (0.3+0.6+0.9)/3 , … ]。
余弦相似度算法
余弦相似度 = (A · B) / (||A|| * ||B||)
其中,A · B 表示向量 A 与向量 B 的点积(内积),||A|| 和 ||B|| 分别表示向量 A 和向量 B 的模长。
根据计算得到的余弦相似度,按照相似度的大小进行排序,从高到低或从低到高。可以选择返回与查询向量最相似的前 k 个结果。
通过以上步骤,可以在向量数据库中使用余弦相似度算法进行查询,找到与查询向量最相似的向量。这种方法常用于文本搜索、推荐系统、图像检索等任务,其中向量表示被用来衡量数据之间的相似性。需要注意的是,对于大规模的数据库和高维向量,可能需要优化的近似算法来加速相似度计算过程。
向量数据库
信息向量化的概念可以追溯到上世纪50年代和60年代的信息检索领域。在这个时期,研究人员开始关注如何将文本和文档表示为数值向量,以便进行计算机处理和检索。
一项重要的里程碑是在1958年提出的向量空间模型(Vector Space Model),由Gerard Salton等人提出。向量空间模型将文本或文档表示为向量,其中每个维度对应于一个特定的词语或特征,而向量的值表示了该词语或特征在文本中的重要性或出现频率。这种基于向量表示的文本检索模型在信息检索领域产生了广泛影响,并成为后续研究的基础。
向量数据库是一种专门用于存储和查询向量数据的数据库系统。它提供高效的存储和检索机制,能够处理大规模的高维向量数据,如文本、图像、音频等。
向量数据库的设计和实现通常需要考虑以下几个方面:
存储结构:向量数据库需要设计适当的数据结构来存储向量数据。常见的存储结构包括基于数组或基于哈希表的索引结构,以及树结构(如B树、R树、VP树等)。这些结构可以支持高效的向量存储和检索操作。
距离度量:向量数据库需要支持不同的距离度量方法,用于计算向量之间的相似性或距离。常见的距离度量包括欧氏距离、余弦相似度、曼哈顿距离等。合适的距离度量方法可以在查询时准确度量向量之间的相似性。
索引和检索:为了加速向量检索操作,向量数据库通常会建立索引结构。索引可以基于向量的特征或属性构建,以便快速定位相关的向量。常见的索引方法包括倒排索引、KD树、LSH(局部敏感哈希)等。
查询优化:向量数据库需要优化查询操作,以提高检索效率和准确性。这包括使用合适的索引策略、查询重写和优化、并行处理等技术,以实现高效的向量查询。
扩展性和容错性:向量数据库需要支持扩展性和容错性,以适应大规模数据和高并发查询的需求。
使用场景
- chatgpt额外的信息库
- 人脸识别
1). 人脸检测:在图像或视频中检测和定位人脸区域。这一步骤使用的通常是基于机器学习或深度学习的人脸检测算法。
2). 人脸对齐:对检测到的人脸进行对齐,将其调整为标准化的姿态和尺寸。这一步骤有助于减少不同图像之间的差异性,提高后续特征提取的准确性。
3). 特征提取:从对齐后的人脸图像中提取关键特征。这些特征通常表示为一个向量,被称为人脸特征向量或人脸嵌入。特征提取算法可以使用传统的计算机视觉方法,如局部二值模式(Local Binary Patterns,LBP),也可以使用深度学习模型,如卷积神经网络(Convolutional Neural Networks,CNN)。
4). 向量比对和匹配:将待识别的人脸特征向量与已存储的人脸特征向量进行比对和匹配。常见的向量算法包括欧氏距离、余弦相似度和曼哈顿距离等。通过计算两个向量之间的相似度或距离,并设定一个阈值,系统可以判断人脸是否匹配,从而实现人脸识别。 - 指纹识别
指纹图像的转换通常使用特征提取算法,将指纹图像中的关键特征提取出来,并将其转换为向量形式。这些特征可以包括指纹纹线的形状、方向、交叉点等。
chroma
https://github.com/chroma-core/chroma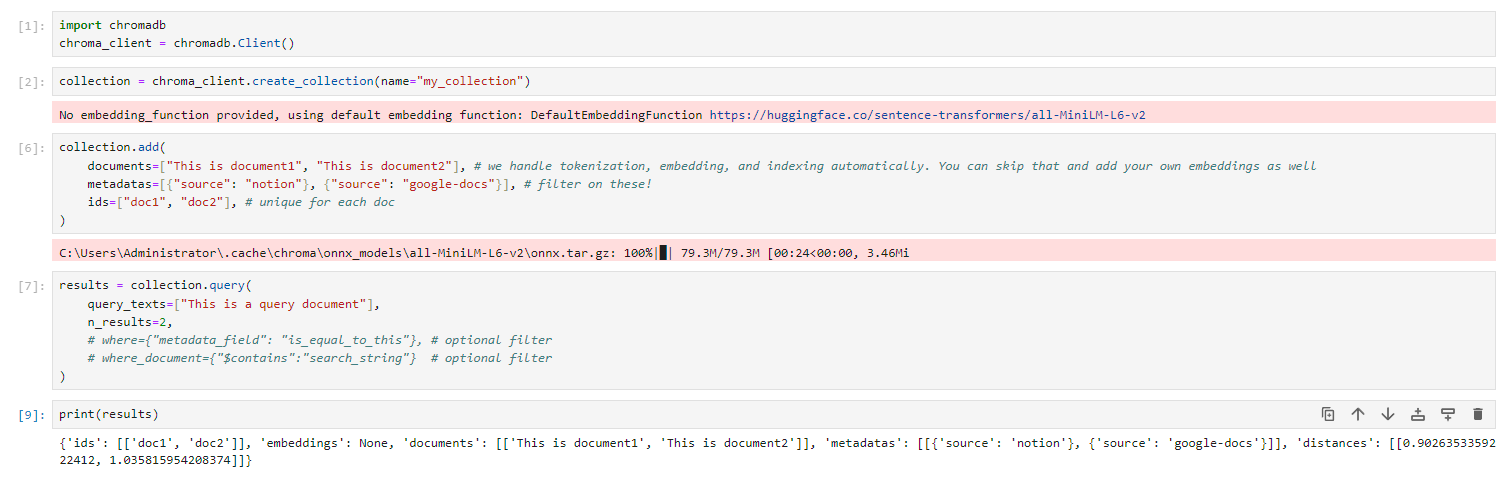
openai api获取embedding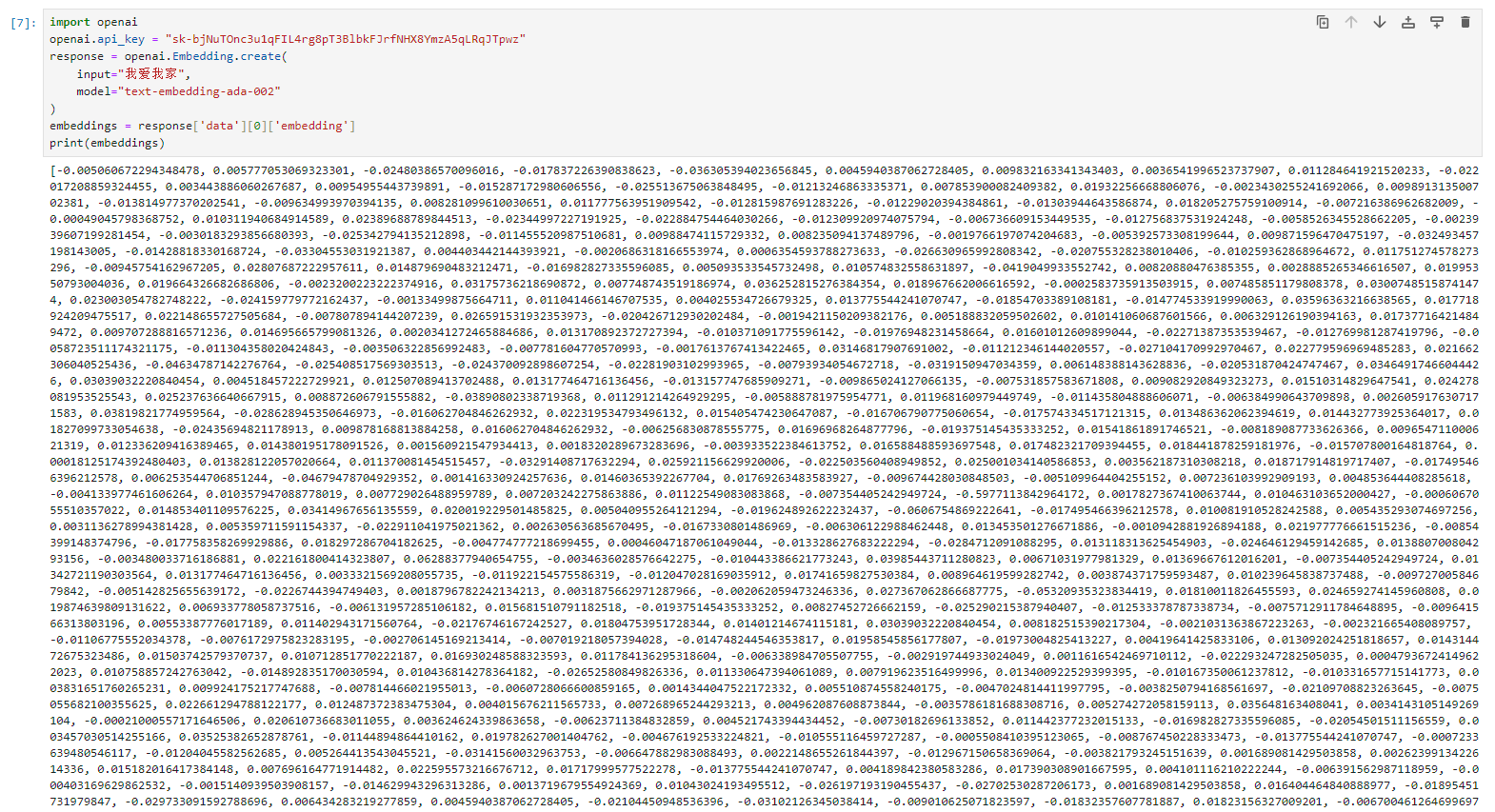
常见算法
- 向量索引算法:向量数据库通常需要构建索引结构以支持高效的向量检索。常见的向量索引算法包括 KD-Tree、Ball Tree、R-Tree、VP-Tree 等。这些算法可以将向量空间划分为多个子空间,以快速定位和检索相似的向量。
- 相似度度量算法:在向量数据库中,需要计算向量之间的相似度或距离,以进行相似性查询和排序。常用的相似度度量算法包括欧氏距离、余弦相似度、曼哈顿距离、Jaccard 相似系数等。这些算法可以衡量向量之间的相似性或差异性,从而实现向量的比较和排序。
- 聚类算法:聚类算法用于将相似的向量分组到同一簇中,以便更有效地组织和管理向量数据。常见的聚类算法包括 K-Means、层次聚类、DBSCAN 等。这些算法可以根据向量之间的相似性将它们划分为不同的簇,提供更快速的数据访问和分析。
- 降维算法:在大规模高维向量数据中,降维算法用于减少数据维度,以节省存储空间和提高计算效率。常用的降维算法包括主成分分析(Principal Component Analysis,PCA)、t-SNE、LLE 等。这些算法可以将高维向量映射到低维空间,保留向量之间的相似性信息。
- 哈希算法:哈希算法用于将向量映射到哈希码,以实现高效的近似相似性搜索。常见的哈希算法包括 Locality Sensitive Hashing(LSH)、MinHash、SimHash 等。这些算法可以将向量映射到哈希码,使得相似的向量有更高的概率具有相似的哈希码,从而加速相似性搜索。
欧式距离
欧氏空间中两个向量之间的距离
1 | d = √((x₁ - y₁)² + (x₂ - y₂)² + ... + (xn - yn)²) |
曼哈顿距离
沿坐标轴移动所需的最短路径长度
1 | d = |x₁ - y₁| + |x₂ - y₂| + ... + |xn - yn| |
Jaccard 相似系数
两个集合交集元素数量与并集元素数量的比值
1 | J(A, B) = |A ∩ B| / |A ∪ B| |